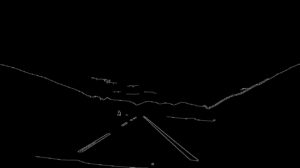
Since the Hough transform returns all line segments, not only those around lane markers, it is necessary to filter the results.
We create two lines that describe boundaries of the current lane (hypothesis).
We place two converging lines in the frame.
Using brute-force search, we try to find position where they capture as many line segments as possible.
Since road in the frame can have more than one lane, we try to find result as narrow as possible.
We select line segments that are captured by the created hypothesis, mark them as lane markers and draw them.
Each frame, we take the detected lane markers from the previous frame and perform linear regression to adjust the hypothesis (continuous adjustment).
If we cannot find lane markers in more than 5 successive frames (due to failure of continuous adjustment, lane change, intersection, …), we create a new hypothesis.
If the hypothesis is too wide (almost full width of the frame), we create a new one, because arrangement of road lanes might have changed (e.g. additional lane on freeway).
To distinguish between solid and dashed lane markers, we calculate coverage of the hypothesis by line segments. If the coverage is less than 60%, it is a dashed line; if more, it is a solid line.
Filtered result of the Hough transform + detection of solid/dashed lines.
The goal of this project is to determine the state of a parking lot, more precisely the number of parking spaces. Basically this project is divided to two interconnected parts. One to determine number of parking spots from image, for example from first frame of video from camera, monitoring the parking lot, and second to determine wheter, or not is there a movement on the parking lot.
The process:
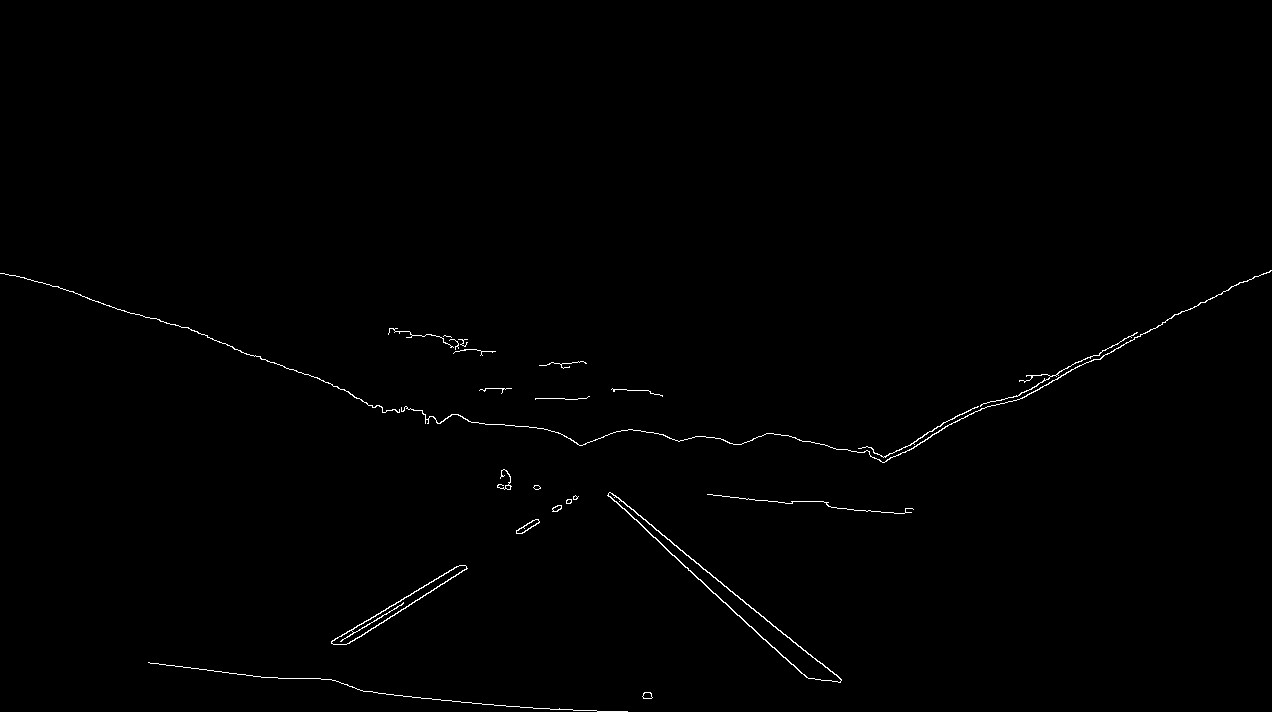
We get parking lines from image of parking lot and get rid of noise:
Result of Hough lines to remove connection between lines in mask
We use this as a mask for finding contours for the Watershed algorithm and get result with detected parking spots, each colored with different color:
vector<vector<Point> > contours;
vector<Vec4i> hierarchy;
findContours(markerMask, contours, hierarchy, RETR_CCOMP, CHAIN_APPROX_SIMPLE);
int contourID = 0;
for (; contourID >= 0; contourID = hierarchy[contourID][0], parkingSpaceCount++)
{
drawContours(markers, contours, contourID, Scalar::all(parkingSpaceCount + 1), -1, 8, hierarchy, INT_MAX);
}
watershed(helpMatrix2, markers);
Mat wshed(markers.size(), CV_8UC3);
for (i = 0; i < markers.rows; i++)
for (j = 0; j < markers.cols; j++)
{
int index = markers.at<int>(i, j);
if (index == -1)
wshed.at<Vec3b>(i, j) = Vec3b(255, 255, 255);
else if (index <= 0 || index > parkingSpaceCount)
wshed.at<Vec3b>(i, j) = Vec3b(0, 0, 0);
else
wshed.at<Vec3b>(i, j) = colorTab[index - 1];
}
Result of watershed algorithm with detected parking spots
If our user is not satisfied with this result, he can always draw the seeds for watershed himself, or just adjust these seeds (img is the name of matrix, where user can see markers and markerMask matrix, where seeds are stored):
Point prevPt(-1, -1);
static void onMouse(int event, int x, int y, int flags, void*)
{
if (event == EVENT_LBUTTONDOWN) prevPt = Point(x, y);
else if (event == EVENT_MOUSEMOVE && (flags & EVENT_FLAG_LBUTTON))
{
Point pt(x, y);
if (prevPt.x < 0)
prevPt = pt;
line(markerMask, prevPt, pt, Scalar::all(255), 5, 8, 0);
line(img, prevPt, pt, Scalar::all(255), 5, 8, 0);
prevPt = pt;
imshow("image", img);
}
}
User inputing seeds for watershed algorithm
We have our spots stored, so we know their exact location, now its time to determine, wheter, or not check the lot again, if some vehicles are moving. For this purpose we need to detect movement on the lot with backgroundSubstraction, which can constantly learn what is static in image:
Ptr<BackgroundSubtractor> pMOG2;
pMOG2 = new BackgroundSubtractorMOG2(3000, 20.7,true);
We will give the MOG every frame captured from video feed and see what it results:
Finally we find coordinates of moving object from MOG and draw a rectangle with random color around it (result can be seen at the top):
scv::findContours(matMaskMog2, contours, CV_RETR_EXTERNAL, CV_CHAIN_APPROX_NONE);
vector<vector<Point> > contours_poly(contours.size());
vector<Rect> boundRect(contours.size());
for (int i = 0; i < contours.size(); i++)
{
approxPolyDP(Mat(contours[i]), contours_poly[i], 3, true);
boundRect[i] = boundingRect(Mat(contours_poly[i]));
}
RNG rng(01);
for (int i = 0; i< contours.size(); i++)
{
Scalar color = Scalar(rng.uniform(0, 255), rng.uniform(0, 255), rng.uniform(0, 255));
rectangle(frame, boundRect[i].tl(), boundRect[i].br(), color, 2, 8, 0);
}
Result:
We have a functional parking spot detection, which means we can easily determine how much parking spots our parking lot have. We also have stored where are these parking spots exactly located. From the camera feed, we can detect car movement and also determine, on which coordinates the movement stopped. We did not implemented the function to connect these infomormation sources, but it can be easily added.
Limitations:
For parking spots detection we need an empty lot. Otherwise it will be nearly impossible to determine where are these spots exactly located, mainly if vehicles are not parking at their exact center.
For movement detection, we need static camera feed, becouse of used MOG method, which constantly learns what is background and which object are moving.
Parking spots detection is not perfect, it still needs some user correction to determine exact number of parking spots.
We detect cars from videos recorded by dash cameras situated in cars. This type of camera is dynamic so we decided to train and use Haar Cascade Classifier. The classifier itself returns a lot of false positive results. So we improved classifier by removing false positive results using road detection.
Collect a set of positive samples and negative samples. Make a list file of both (positives.dat and negatives.dat). Then use opencv_createsamples function with parameters to make a single .vec file with all positive samples.
The goal of this project is to detect card in captured image. Motivation was to make automatized recognizer of cards for poker tournaments. Application is implemented to find orthogonal edges in an image and try to find card by ratio of its edges.
Process of finding and recognizing a card in image follows these steps:
Load an image from local repository.
Apply blur and bilateral filter.
Compute binary threshold.
Extract edges from binary image by Canny algorithm.
Apply Hough lines to get lines find in edge image.
Search for orthogonal lines and store them in structure for future optimalization.
Optimise number of detected lines in same area by choosing only the biggest ones.
Find card which consist of 3 touching lines.
Compute ratio of the lines and identify cards in the image.
Following code sample shows steps of optimalization of detected corners:
vector<MyCorner> optimalize(vector<MyCorner> corners, Mat image) {
vector<MyCorner> optCorners;
for (int i = 0; i < corners.size(); i++) {
corners[i].crossing = crossLines(corners[i]);
corners[i].single = 1;
}
int distance = 25;
for (int i = 0; i < corners.size() - 1; i++) {
MyCorner corner = corners[i];
float lengthI = 0, lengthJ = 0;
if (corner.single){
for (int j = i + 1; j < corners.size(); j++) {
if (abs(corner.crossing.x - corners[j].crossing.x) < distance && abs(corner.crossing.y - corners[j].crossing.y) < distance &&
(corner.single || corners[j].single)) {
lengthI = getLength(corner.u) + getLength(corner.v);
lengthJ = getLength(corners[j].u) + getLength(corners[j].v);
if (lengthI < lengthJ) {
corner = corners[j];
}
corner.single = 0;
corners[i].single = 0;
corners[j].single = 0;
}
}
optCorners.push_back(corner);
}
}
return optCorners;
}
We implement well-known Bag of Words algorithm (BoW) in order to perform image classification of tiger cat images. In the work, we use a subset of publicly available ImageNet dataset and divide data on two sets – tiger cats and non-cat objects, which consist of images of 10 random chosen object types.
The main processing algorithm is performed by these steps:
Choose a suitable subset of images from a large dataset
We use around 100 000 unique images
Detect keypoints
We detect keypoints using SIFT or Dense keypoint extractor
DenseFeatureDetector dense(20.0f, 3, 2, 10, 4);
BOWKMeansTrainer bowTrainer(dictionarySize, tc, retries, flags);
for (int i = 0; i < list.count(); i++){
Mat img = imread(list.at(i), CV_LOAD_IMAGE_COLOR);
dense.detect(img, keypoints);
}
Keypoints detected using SIFT detect function – more than 500 keypoints.
Describe keypoints using SIFT
SIFT descriptor produces description for each keypoint separately
Try detect objects (players, soccer ball, referees, goal keeper) in soccer match. Detect their position, movement and show picked object in ROI area. More info in a presentation and description document.
T. D’Orazio, M.Leo, N. Mosca, P.Spagnolo, P.L.Mazzeo A Semi-Automatic System for Ground Truth Generation of Soccer Video Sequences in the Proceeding of the 6th IEEE International Conference on Advanced Video and Signal Surveillance, Genoa, Italy September 2-4 2009
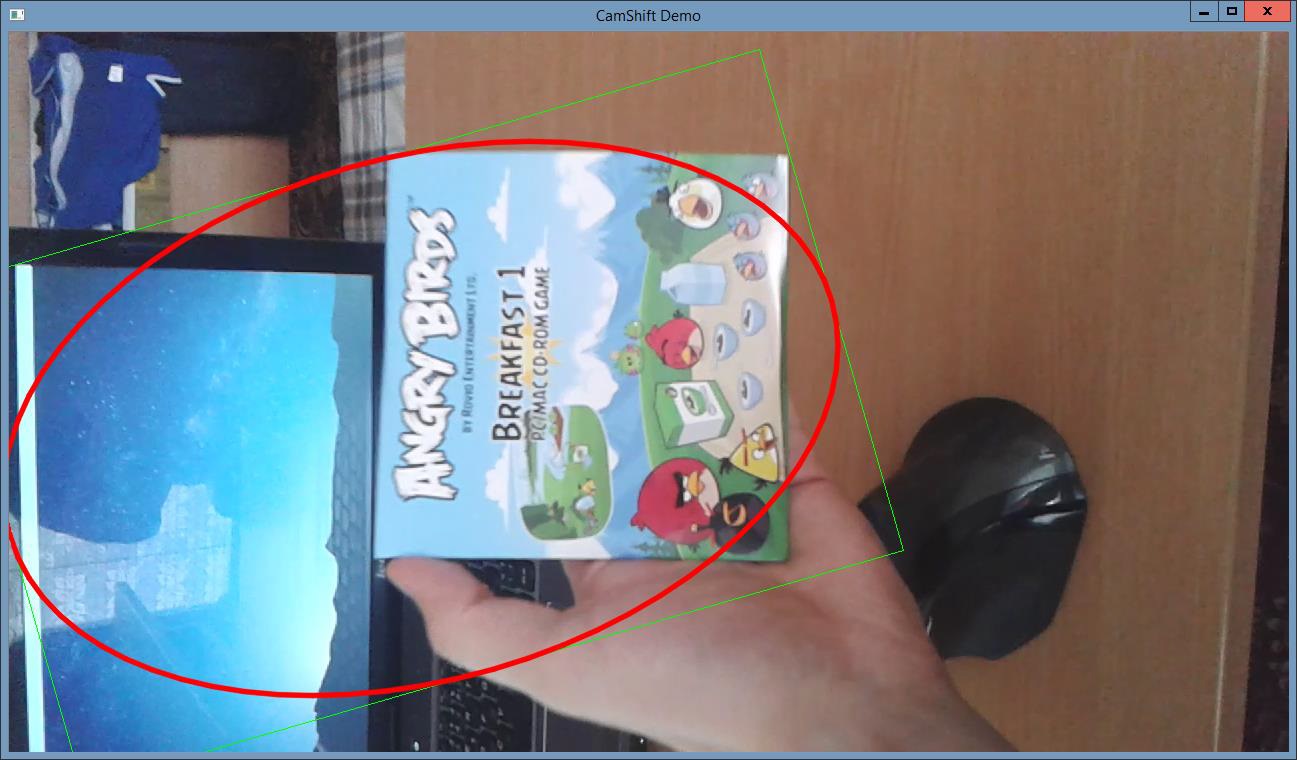
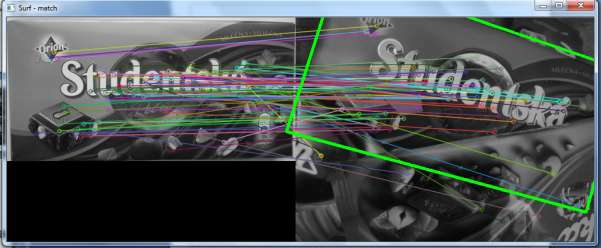
In our project we focus on simple object recognition, then tracking this recognized object and finally we try to delete this object from video. By object recognition we used local features-based methods. We compare SIFT and SURF methods for detection and description. By RANSAC algorithm we compute the homography. In case these algorithms successfully find the object we create a mask where recognized object was white area and the rest was black. By object tracking we compared the two approaches. The first approach is based on calculating optical flow using the iterative Lucas-Kanade method with pyramids. The second approach is based on camshift tracking algorithm. For deleting the object from video we focus to using algorithm based on restoring the selected region in an image using the region neighborhood.
The project shows detection of chocolate cover from input image or frame of video. For each video or image may be chosen various combinations of detector with descriptor. For matching object of chocolate cover with input frame or image automatically is used FlannBasedMatcher or BruteForceMatcher. It depends on the chosen SurfDescriptorExtractor or FREAK algorithm.
Smile detection is a popular feature of today’s photo cameras. It is not implemented in all cameras, as a popular face detection, because it is more complicated to implement. This project shows a basic algorihtm in the topic. It may be used but few improvements are necessary. Sobel filter and thresholding are used. There is a mask which is compared to every filtered image from a webcam. If the images are more than 60% equal, smile is detected. Used Functions detectMultiScale, Sobel, medianBlur, threshold, dilate, bitwise_and
In this example we focus on enhancing the current SIFT descriptor vector with additional two dimensions using depth map information obtained from kinect device. Depth map is used for object segmentation (see: http://vgg.fiit.stuba.sk/2013-07/object-segmentation/) as well to compute standard deviation and the difference of minimal and maximal distance from surface around each of detected keypoints. Those two metrics are used to enhance SIFT descriptor.
To be able to enhance SIFT descriptor and still provide good matching results, we need to evaluate the precision of selected metrics. We have chosen to visualize the normal vectors computed from the surface around keypoints.
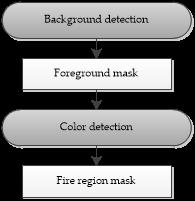
The main aim of this example is to automatically detect fire in video, using computer vision methods, implemented in real-time with the aid of the OpenCV library. Proposed solution must be applicable in existing security systems, meaning with the use of regular industrial or personal video cameras. Necessary solution precondition is that camera is static. Given the computer vision and image processing point of view, stated problem corresponds to detection of dynamically changing object, based on his color and moving features.
While static cameras are utilized, background detection method provides effective segmentation of dynamic objects in video sequence. Candidate fire-like regions of segmented foreground objects are determined according to the rule-based color detection.
Input
Process outline
Process steps
Retrieve current video frame
capture.retrieve(frame);
Update background model and save foreground mask to
BackgroundSubtractorMOG2 pMOG2;
Mat fgMaskMOG2,
pMOG2(frame, fgMaskMOG2);
Convert current 8-bit frame in RGB color space to 32-bit floating point YCbCr color space.
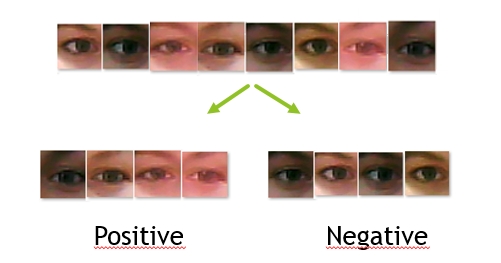
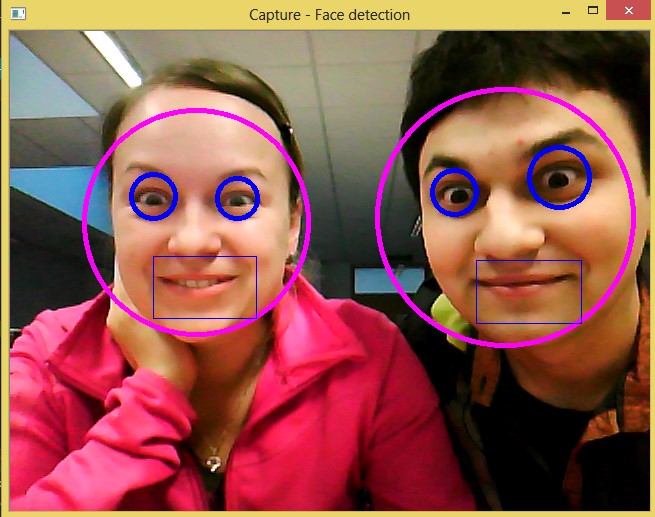
The project shows detection and recognition of face and eyes from input image (webcam). I use for detection and classification haarcascade files from OpenCV. If eyes are recognized, I classify them as opened or narrowed. The algorithm uses the OpenCV andSVMLight library.
As first I make positive and negative dataset. Positive dataset are photos of narrowed eyes and negative dataset are photos of opened eyes.
Then I make HOGDescriptor and I use it to compute feature vector for every picture. These pictures are used to train SVM vector and their feature vectors are saved to one file: features.dat
I detect every face and every eye from picture. For every found picture of eye I cut it and I use HOGDescriptor to detect narrowed shape of eye.
Face, Eye and Mouth detectionCutting eyes and conversion to grayscale format