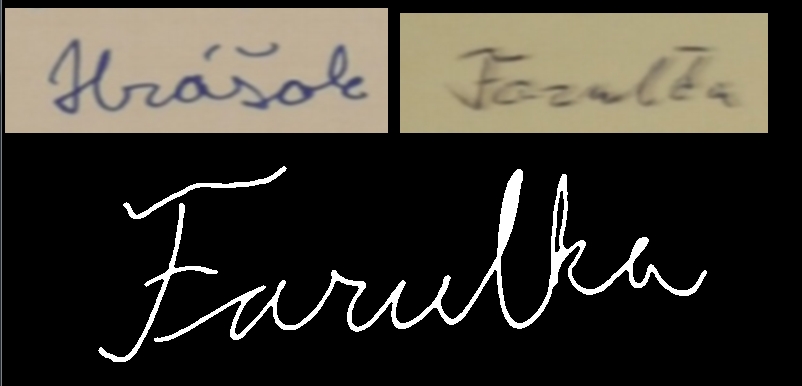
Matej Stetiar
Main purpose of this project was to recognise signatures. For this purpose we used descriptor from the bottom of the signature. Then we used Mahalanobis distance to identify signatures.
Image preprocessing
We have worked with 2 sets of signatures and each of them had about 200 pictures of signatures. Examples of those signatures are below.

The signatures had different quality. So we decided to find skeleton of them.
Mat skel(tmp_image.size(), CV_8UC1, Scalar(0));
Mat tmp(tmp_image.size(), CV_8UC1);
Mat structElem = getStructuringElement(MORPH_CROSS, Size(3, 3));
do
{
morphologyEx(tmp_image, tmp, MORPH_OPEN, structElem);
bitwise_not(tmp, tmp);
bitwise_and(tmp_image, tmp, tmp);
bitwise_or(skel, tmp, skel);
erode(tmp_image, tmp_image, structElem);
double max;
minMaxLoc(tmp_image, 0, &max);
done = (max == 0);
} while (!done);

Then we decided to find contours and filter them according to their size to remove the noise.
vector<vector<Point>> contours;
vector<Vec4i> hierarchy;
findContours(image, contours, hierarchy, CV_RETR_TREE, CV_CHAIN_APPROX_SIMPLE);
Mat drawing = Mat::zeros(image.size(), CV_8UC1);
for (int i = 0; i< contours.size(); i++){
if (contours[i].size() < 10.0) continue;
Scalar color = Scalar(255);
drawContours(drawing, contours, i, color, CV_FILLED, 8, hierarchy);
}
The result of image preprocessed like this can be seen below. This picture has very thick lines so we decided to add contour image and skeleton image together.

For purpose of adding 2 images together we used logical function AND.
bitwise_and(newImage, skeleton, contours);
The result of this process was signature with thin line with no noise.
Creating descriptors
To create descriptors we used bottom line of the signature. To lower the factor of length of signature we always divided signature to 25 similar pieces. Space between these pieces was calculated dynamically. The descriptor was gathered as maximum of white point position in each of 25 division points.
To reduce the factor that signature is written in some angle we transformed the points to lower positions. To do so we gathered points in 10° range from lowest point. Then we calculated average of these points. Then we used linear regression to add coefficient to all points. Linear regression was made using maximal point and average of the other points.
Descriptor we created had counted with different lengths of signatures and different angles of signatures. So the last step was to normalise the height. To do so we subtracted minimum point of the signature from all points and then we divided all points with maximum from descriptor.
Learning phase
We created 2 sets of descriptors each with 180 examples. From these descriptors we created 2 objects of class Signature.
class Signature
{
std::string name; //signature name
cv::Mat centorid; //centorid created from learning set
cv::Mat covarMat; //covariance matrix created form lenrning set
};
To recognition of the signatures we wanted to use Mahalanobis distance method. To do so we needed centroid for our data set and inverse covariance matrix. We calculated those using functions:
cv::calcCovarMatrix(samples, this->covarMat, this->centorid, CV_COVAR_NORMAL | CV_COVAR_ROWS); cv::invert(this->covarMat, this->covarMat, cv::DECOMP_SVD);
In code above the variable samples is representing the matrix of all samples.
Testing
After we created inverse covariance matrix and centroid we could start testing. Testing of the signature was creating its descriptor using same steps as when creating descriptors in testing set. Then we could call function to calculate Mahalanobis distance.
Mahalanobis(testSample, this->mean, this->covarMat);
Using this algorithm we were able to identify some of the signatures. But the algorithm is very sensitive to changes in image quality and number of items in training set.