Description
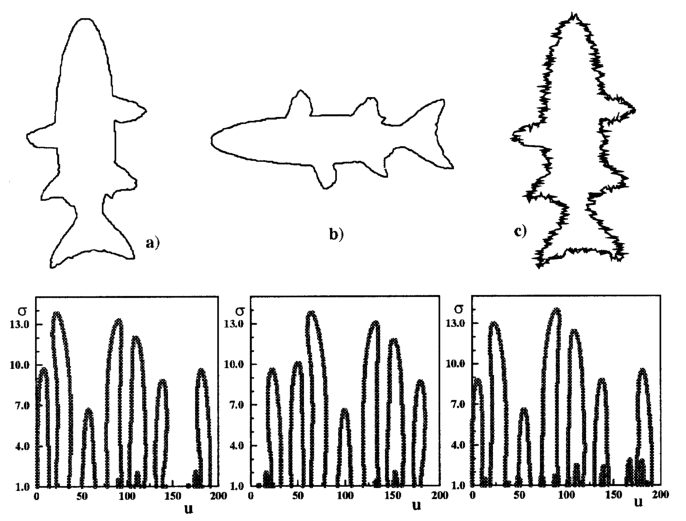
The goal of this project is to implement algorithm that creates curvature scale space (CSS) image of given shape using OpenCV library. “The CSS image consists of several arch-shape contours representing the inflection points of the shape as it is smoothed. The maxima of these contours are used to represent a shape. The CSS representation is robust with respect to scale, noise and change in orientation.â€[1]

Process
- Find contour coordinates of given shape
- Gaussian kernel is the base for upcoming steps:
transpose(getGaussianKernel(width, sigma, CV_64FC1), G);
-
Curve evolution can be computed by convolution of contour points with Gaussian kernel. Smoothed contour is not needed for CSS computation; it is used only to visualize the process:
filter2D(X, Xsmooth, X.depth(), G); filter2D(Y, Ysmooth, Y.depth(), G);

Curve evolution with increasing sigma [2] - To compute 1st and 2nd derivation of contour points, Gaussian kernel derivations will be needed:
Sobel(G, dG, G.depth(), 1, 0, 3); Sobel(G, ddG, G.depth(), 2, 0, 3);
- Convolution of contour points using derivatives of Gaussian kernel. According to OpenCV documentation: filter2D does actually computes correlation, not the convolution. That is, the kernel is not mirrored around the anchor point. If you need a real convolution, flip the kernel using flip() and set the new anchor to (kernel.cols – anchor.x – 1, kernel.rows – anchor.y – 1) :
flip(dg, dg, 0); flip(ddg, ddg, 0); Point anchor(dg.cols - fwhm -1, dg.rows - 0 - 1); filter2D(X, dX, X.depth(), dG, anchor); filter2D(Y, dY, Y.depth(), dG, anchor); filter2D(X, ddX, X.depth(), ddG, anchor); filter2D(Y, ddY, Y.depth(), ddG, anchor);
- Finally, we calculate the curvature and find zero crossings:

Curvature and inflection points of curve smoothed with sigma=16 - Zero-crossing points are plotted to the final CSS image. X-axis represents position of point on the curve; Y-axis represents the value of sigma:

Final CSS image with zero-crossing points for all sigmas
findContours(im, contours, CV_RETR_LIST, CV_CHAIN_APPROX_NONE );
Following steps are repeated with increased sigma until there are no zero-crossing points:
Practical Applications
- Finding similar shapes  (Used as shape descriptor in MPEG-7 standard)
- Corner detection

References
[1] Sadegh Abbasi, Farzin Mokhtarian, Josef Kittler: Curvature Scale Space Image in Shape Similarity Retrieval. Multimedia Syst. 7(6): 467-476 (1999)
[2] Farzin Mokhtarian, Alan K. Mackworth: A Theory of Multiscale, Curvature-Based Shape Representation for Planar Curves. IEEE Trans. Pattern Anal. Mach. Intell. 14(8): 789-805 (1992)