Description
Convolutional Neural Networks(CNNs) are multi-layered neural networks with standard hidden layers and with at least one convolutional layer. They are suitable for visual processing because they exploit the tolopogy of inputs.
Because we are interested in more general structures of networks and layers, the CNN is implemented with automatic differentiation (AD) in mind. This means that one has to provide only the implementation of forward pass of any structure. It is important to note that AD is based on certainly different principle as finite differences. The important difference of AD is that it yields precise results.
Architecture
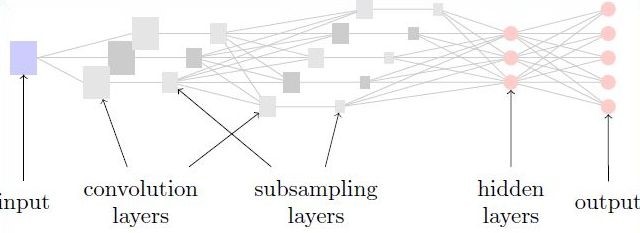
The architecture of convolutional networks is shown in figure 1. Convolutional layers are located right after inputs. After each convolutional layer the process of subsampling is performed. By subsampling we improve translational invariance and significantly reduce complexity. After convolutional layers, standard fully connected hidden layers are used. These are then mapped to desired outputs.

When the signal passes into standard hidden layer, it is no longer meaningful to pass it again into another convolutional layers. However it can be meaningful to have heterogeneous layers consisting of convolutional and also standard units.
Experiments
Note that it is meaningful for input to be two-dimensional. We have used CNN for handwritten digits recognition of US Postal Service.
- 2,5% human error rate
- 2,0% best error rate: combination of multiple classifiers
- 4,7% best achievement of our CNN
We note, that CNNs are sensitive to parameter settings including number and size of convolutional kernels. However, when properly set, CNNs perform well. We can see an example output of convolutional layers at figure 2.
