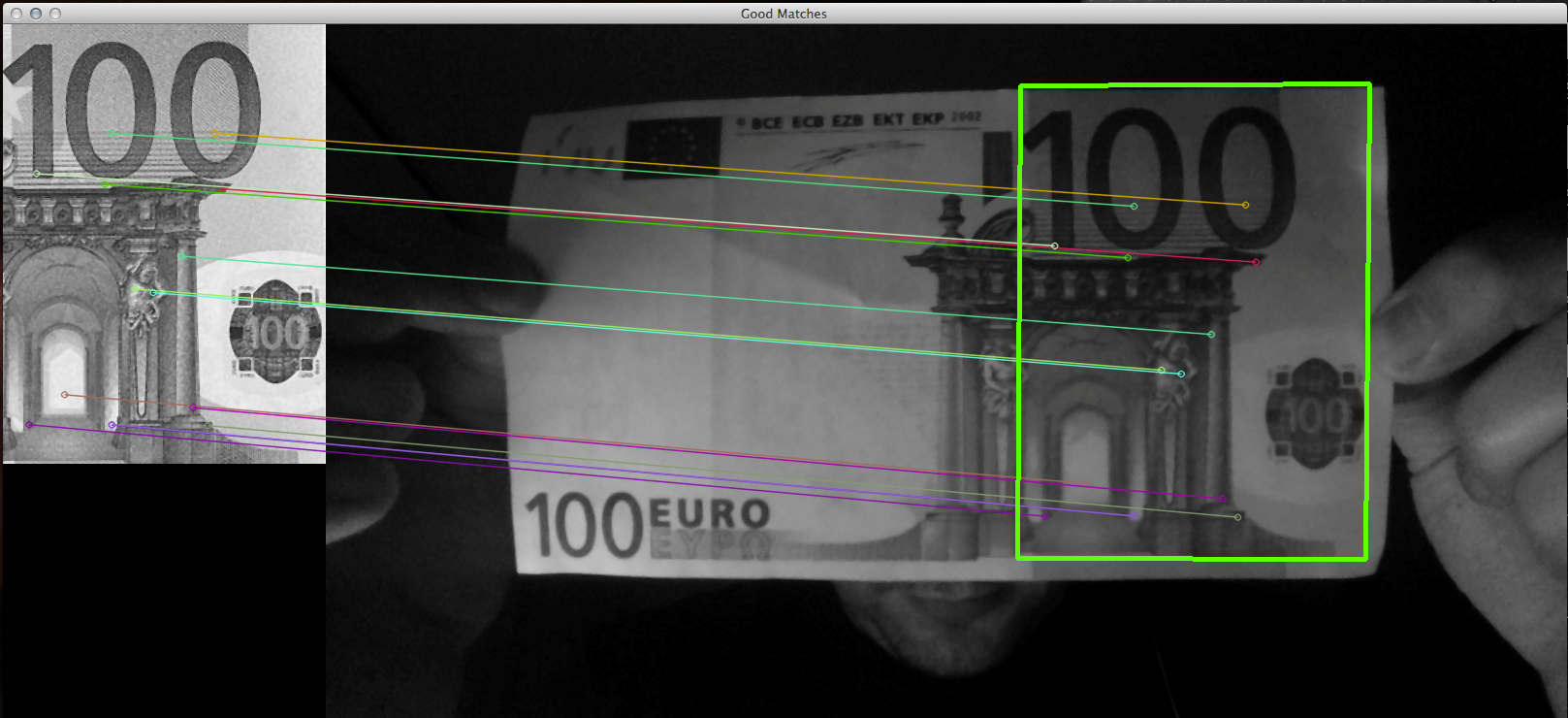
The project shows detection and recognition of euro money bill from input image (webcam). For each existing euro money bill is chosen template that contains number value of bill and also its structure. For matching templates with input images is used Flann Based matcher of local descriptors extracted by SURF algorithm.
Functions used: medianBlur, FlannBasedmatcher, SerfFeatureDetector, SurfDescriptorExtractor, findHomography
Process
- Preprocessing – Conversion to grayscale + median filter
cvtColor(input_image_color, input_image, CV_RGB2GRAY); medianBlur(input_image, input_image, 3);
- Compute local descriptors
SurfFeatureDetector detector( minHessian ); vector<KeyPoint> template_keypoints; detector.detect( money_template, template_keypoints ); SurfDescriptorExtractor extractor; extractor.compute( money_template, template_keypoints, template_image ); detector.detect( input_image, input_keypoints ); extractor.compute( input_image, input_keypoints, destination_image );
- Matching local descriptors
FlannBasedMatcher matcher; matcher.knnMatch(template_image, destination_image, matches, 2);
- Finding homography and drawing output
Mat H = findHomography( template_object_points, input_object_points, CV_RANSAC ); perspectiveTransform( template_corners, input_corners, H); drawLinesToOutput(input_corners, img_matches, money_template.cols);
Sample