Moodle course AI in HCI
Prednášky 2024
Prednášky 2023
Cvika 2024
 Abstract: The aim of this paper is to propose a novel method to explain, interpret, and support the decision-making process of deep Convolutional Neural Network (CNN). This is achieved by analyzing neuron activations of trained 3D-CNN on selected layers via Gaussian Mixture Model (GMM) … more
Abstract: The aim of this paper is to propose a novel method to explain, interpret, and support the decision-making process of deep Convolutional Neural Network (CNN). This is achieved by analyzing neuron activations of trained 3D-CNN on selected layers via Gaussian Mixture Model (GMM) … more
 Ing. Patrik Polatsek – Dissertation thesis
Ing. Patrik Polatsek – Dissertation thesisMODELLING OF HUMAN VISUAL ATTENTION
Degree Course: Applied Informatics
Author: Ing. Patrik Polatsek
Supervisor: doc. Ing. Vanda Benesova, PhD.
Slovak University of Technology Bratislava, FACULTY OF INFORMATICS AND INFORMATION TECHNOLOGIES, May 2019, … more

Download: Master Thesis- Martin Tamajka: Segmentation of anatomical organs in medical data
Annotation:
2016, May
Medical image segmentation is an important part of medical practice. Primarily as far as radiologists are concerned it simplifies their everyday tasks and allows them to use their time more effective, because in most cases radiologists only have a certain amount of time they can spend examining patient’s data. Computer aided diagnosis is also a powerful instrument in elimination of possible human failure.
In this work, we propose a novel approach to human organs segmentation. We primarily concentrate on segmentation of human brain from MR volume. Our method is based on oversegmenting 3D volume to supervoxels using SLIC algorithm. Individual supervoxels are described by features based on intensity distribution of contained voxels and on position within the brain. Supervoxels are classified by neural networks which are trained to classify supervoxels to individual tissues. In order to give our method additional precision, we use information about the shape and inner structure of the organ. In general we propose a 6-step segmentation method based on classification.
We compared our results with those of state-of-the-art methods and we can conclude that the results are clearly comparable.
Apart from the global focus of this thesis, our goal is to apply engineering skills and best practices to implement proposed method and necessary tools in such a way that they can be easily extended and maintained in the future.


Abstract:
In this work, we present a fully automatic brain segmentation method based on supervoxels (ABSOS). We propose novel features used for classification, that are based on distance and angle in different planes between supervoxel and brain center. These novel features are combined with other prominent features. The presented method is based on machine learning and incorporates also a skull stripping (cranium removing) in the preprocessing step. Neural network – multilayer perceptron (MLP) was trained for the classification process. In this paper we also present thorough analysis, which supports choice of rather small supervoxels, preferring homogeneity over compactness, and value of intensity threshold parameter used in preprocessing for skull stripping. In order to decrease computational complexity and increase segmentation performance we incorporate prior knowledge of typical background intensities acquired in analysis of subjects.
2016 International Conference on Systems, Signals and Image Processing (IWSSIP)
23-25 May 2016
Scientific Grant Agency of the Ministry of Education, science, research and sport of the Slovak Republic and the Slovak Academy of Sciences – Â Grant VEGA 1/0625/14.
Visual object class recognition  in video sequences using a linkage of information derived by a semantic local segmentation and a global segmentation of visual saliency.
Visual class objects recognition  is one of the biggest challenges of current research in the field of computer vision. This project aims to explore new methods of recognizing classes of objects in video sequences. In the center of current research in the field of computer vision. This project aims to explore new methods of recognizing classes of objects in video sequences. In the center of research, the focus will be the research of  new methods of semantic segmentation at the local level approach and segmentation of the visual saliency at the global level. An integrating part of the project proposal will be research of intelligent methods of  transfer of information, which will be obtained by the local and global approach using the principle of cooperative agents.

pdf: Visual attention in egocentric field-of-view using RGB-D data
[1] V. Olesova, W. Benesova, and P. Polatsek, “Visual Attention in Egocentric Field-of-view using RGB-D Data .,†in Proc. SPIE 10341, Ninth International Conference on Machine Vision (ICMV 2016), 2016.
You are free to use this dataset for any purpose. If you use this dataset, please cite the paper above.

Martin Volovar
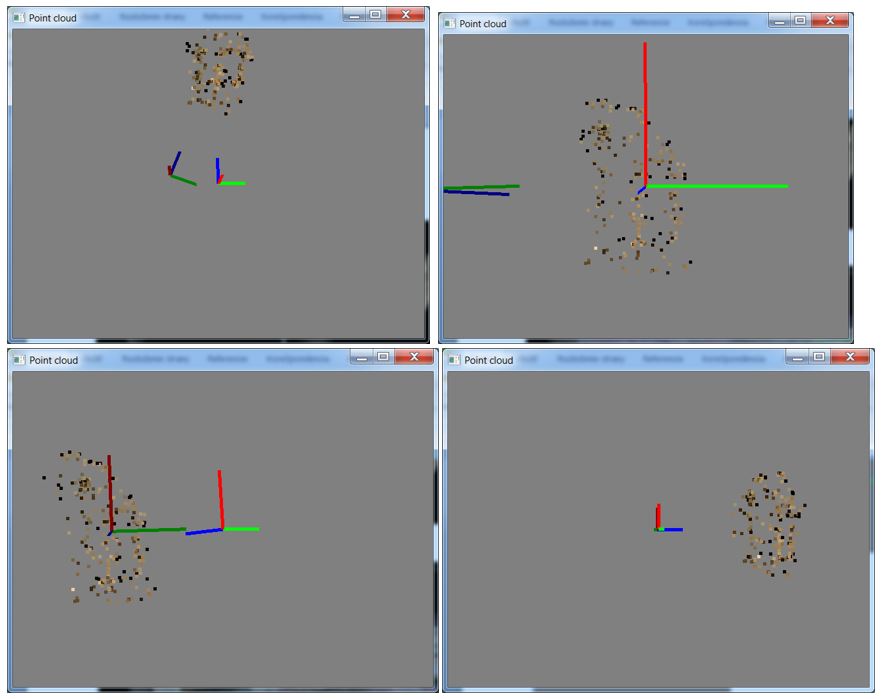
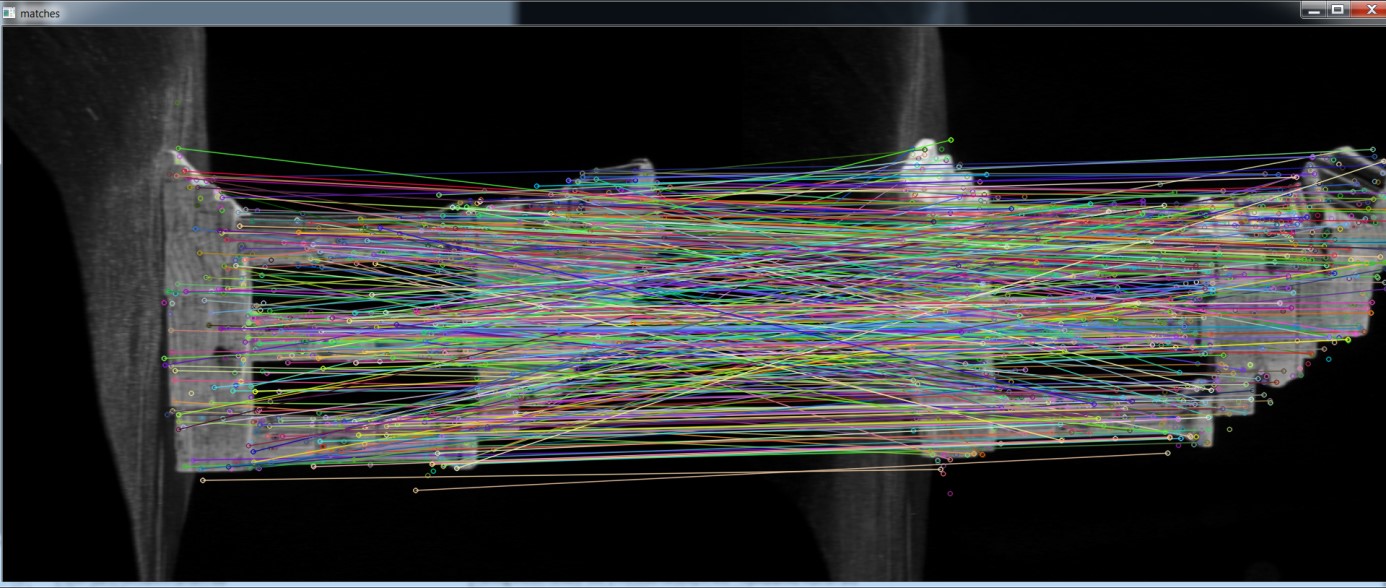
Camera tracking is used in visual effects to synchronize movement and rotation between real and virtual camera .This article deals with obtaining rotation and translation from two images and trying to reconstruct scene.
SurfFeatureDetector detector(400); vector<KeyPoint> keypoints1, keypoints2, findKeypoints; detector.detect(img1, keypoints1); detector.detect(img2, keypoints2); SurfDescriptorExtractor extractor; extractor.compute(img1, keypoints1, descriptors1); extractor.compute(img2, keypoints2, descriptors2);
cv::BFMatcher matcher(cv::NORM_L2, true); vector<DMatch> matches; matcher.match(descriptors1, descriptors2, matches);
x = ABS(x); y = ABS(y); if (x < x_threshold && y < y_threshold) status[i] = 1; else status[i] = 0;
Mat FM = findFundamentalMat(keypointsPosition1, keypointsPosition2, FM_RANSAC, 1., 0.99, status);
we can obtain essential matrix using camera internal parameters (K matrix):
Mat E = K. t() * FM * K;
SVD svd(E, SVD::MODIFY_A) ; Mat svd_u = svd. u; Mat svd_vt = svd. vt; Mat svd_w = svd. w; Matx33d W(0, -1, 0, 1, 0, 0, 0, 0, 1) ; Mat R = svd_u * Mat(W) * svd_vt; Mat_<double> t = svd_u. col(2) ;
Rotation have two solutions (R = U*W*VT or R = U*WT*VT), so we check if camera has right direction:
double *R_D = (double*) R.data; if (R_D[8] < 0.0) R = svd_u * Mat(W.t()) * svd_vt;
To construct rays we need inverse camera matrix (R|t):
Mat Cam(4, 4, CV_64F, Cam_D); Mat Cam_i = Cam.inv();
Both lines have one point in camera center:
Line l0, l1; l0.pos.x = 0.0; l0.pos.y = 0.0; l0.pos.z = 0.0; l1.pos.x = Cam_iD[3]; l1.pos.y = Cam_iD[7]; l1.pos.z = Cam_iD[11];
Other point is calculated via projection plane.
Then we can construct rays and find intersection from each keypoint:
getNearestPointBetweenTwoLines(pointCloud[j], l0, l1, k);