About
Deep generative models such as WaveNet are surprisingly good at various modelling tasks. We exploit the modelling capacity of WaveNet architecture in a setup that is quite different from the original generative case: for feature extraction and pattern recognition in sake of polyphonic music transcription. The model is trained end-to-end to perform the underlying task of multiple fundamental frequency estimation by processing raw waveforms of digital audio signal. This approach shows promise by surpassing baselines, but is not yet ready to compete with concurrent approaches based on top of the hand-crafted spectral features. However, modelling raw audio introduces potential advantages for future extensions of this work in terms of increased sensitivity to various nuances in musical signals, which are required to solve the more complex, less constrained instances of automatic music transcription task (e.g. recognition of instruments, note dynamics, and other expressive features).

Publication
Here is the open access [PDF] of the accepted version (preprint) of the paper as published in IEEE proceedings of IWSSIP 2018 conference.
Code
Implementation of this approach is available in this GitHub repository.
Examples
To present the reader with an idea of the performance of trained transcription model in terms of quality of generated transcriptions, we demonstrate the results on two audio samples.
First sample – an excerpt from a piece by J. S. Bach – is from training distribution. The other one – an excerpt form a piece be Hiromi Uehara – is purposefully from out of training distribution.
Table below shows the transcription results for selected samples. The shade of gray in prediction figures denotes probability of note presence, black for present, white for absent. In the estimation plot, green denotes correct note detections, red shows present but undetected notes, blue absent but falsely detected notes, and white the remaining major case: absent and correctly undetected notes.
| Name of the sample | Predictions (raw, estimated "stochastic" piano roll) | Evaluation results (thresholded predictions vs. labels) |
|---|---|---|
| J.S. Bach - Prelude and Fugue in C minor | 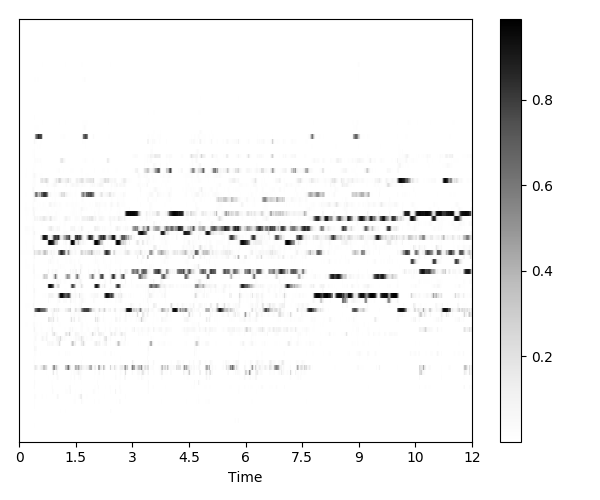 |  |
| Hiromi Uehara - Place to Be | 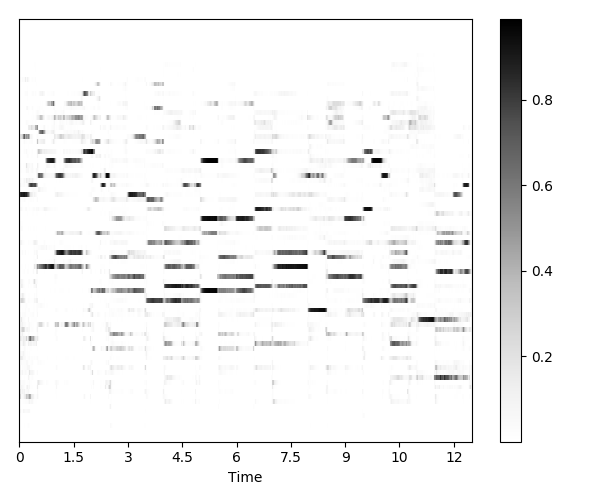 | 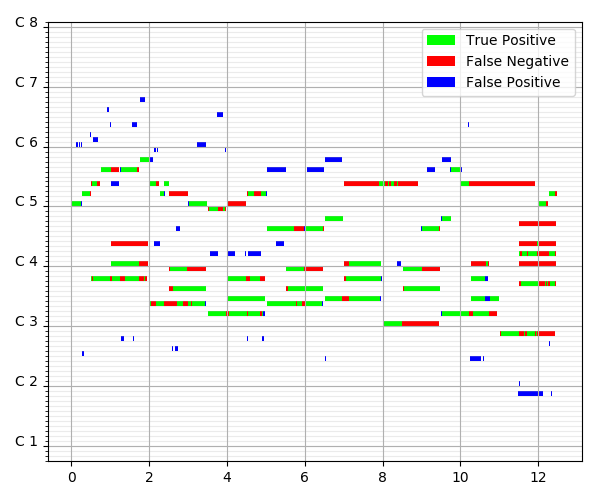 |
For both samples, you can listen to the input and its transcription samples separately, but also overlaid, to hear in contrast if there are some spurious dissonances, or just some disturbing elements in form extremely short false positive notes. Notice the difference in listening quality between the two samples overlaid with their transcriptions.
Cite as
Martak, L. S., Sajgalik, M., & Benesova, W. (2018). Polyphonic Note Transcription of Time-Domain Audio Signal with Deep WaveNet Architecture. 2018 25th International Conference on Systems, Signals and Image Processing (IWSSIP), 1–5. https://doi.org/10.1109/IWSSIP.2018.8439708